
About
Fact Sheet
| Name: | AI-Based Privacy-Preserving Big Data Sharing for Market Research (Anonymous Big Data) |
| Project Number: | 867514 |
| Call: | ICT of the Future, 6th Call 2017 |
| Duration: | 26 months from 01.10.2019 to 30.11.2021. |
| Total Funding: | 671 433 € |
Project Overview
The ANITA (ANonymous bIg daTA) project is a research project funded by the Austrian Research Promotion Agency (ICT of the Future, 6th Call 2017).
The goal of this research project is, for the first time, to train deep generative model architectures to sequential personal data while providing differential privacy guarantees, in order to systematically validate the feasibility of using synthetic, privacy-preserving sequential data for third party market research. ANITA aims to prepare the ground for developing general-purpose anonymization solutions that also work for high-dimensional data.
In ANITA we are going to:
collect and analyze use cases for privacy-sensitive sequential data;
conduct a literature review of generative deep neural network architectures and of privacy guarantees for deep learning;
design and create a virtual data lab that allows to systematically investigate the conditions under which a variety of deep generative models are able to derive synthetic replicas which capture structure and correlations, while protecting individual-level privacy;
implement and test the selected model architectures; and
report the results of the simulation study and of the empirical use case validations.
The consortium partners are the Institute for Service Marketing at the Vienna University of Economics and Business, the Mostly AI Solutions MP GmbH, the George Labs GmbH and the Statistics Austria.
Project Plan
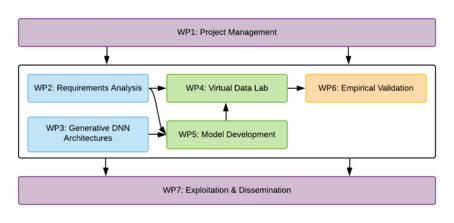
WP1 – Project Management
The general objective of this work package is to support the scientific and technical progress in the best way, so that the main concentration stays on the substantive contribution to the project and the efficient and timely implementation of the work package tasks.
WP2 – Requirements Analysis
The goal of the WP2 is to systematically collect use cases for sharing privacy-sensitive sequential data with third parties as well as to capture requirements with respect to accuracy and privacy.
The use cases will be documented in terms of
number of subjects;
number and characteristics of shared attributes;
frequency / latency for data sharing;
accuracy & privacy requirements;
technical requirements; and
expected (business) impact if the data are anonymized.
WP3 – Generative Deep Neural Network Architectures
WP3’s goal is to gain an overview of generative deep neural network architectures that are deemed capable of preserving individual-level as well as population-level information within sequential personal data, and thus could be used for data anonymization.
In addition to the literature review on generative deep neural network architectures, a literature review will be conducted on the subject of differential privacy guarantees for the training of deep learning models.
WP4 – Virtual Data Lab
WP4’s goal is to setup and run a virtual data lab environment, that can be used for experimentation by generating artificial datasets to be used for validating accuracy and privacy.
A virtual data lab environment will include:
a flexible data factory for generating a variety of artificial sequential datasets;
a GPU cloud compute setup; and
validation tests, measures and visual reports for assessing retained information; and
validation tests and measures for assessing privacy guarantees.
The design of the data lab will be closely aligned with the results of the use case and requirement analysis. Any developed source code relating to the virtual data lab will be open-sourced.
Once the WP5 models have been developed, the data lab will be continuously used to:
generate artificial dataset given model assumptions and parameters;
train models with given hyper parameters to fit the data;
use the models to generate synthetic datasets;
assess the retained information within the synthetic datasets;
assess any disclosed individual-level information within the synthetic datasets; and
record runtime and used compute resources.
WP5 – Model Development
WP5’s goal is to provide reference implementations of existing generative deep neural network architectures, including privacy preserving techniques, and as well refine existing architectures for meeting the captured requirements towards synthetic data.
Based on the outcome of WP3, a list of already published deep neural network architectures will be implemented on top of an established deep learning framework. If available, the correctness of the implementation will be established against published reference results. All implementations will be coupled with various types of privacy-preserving mechanisms, to be able to limit the amount of information that is retained about individual subjects. The software will be designed to be compatible with the virtual data lab, and in particular allow easy tuning of various parameters, in order to quickly iterate on different choices hyper parameters and network settings. Further, existing model architectures could be refined in order to meet the requirements established by WP2.
WP6 – Empirical Validation
WP6’s goal is to validate the feasibility of using synthetic data in lieu of actual data for market research purposes with actual empirical use cases provided by the consortium partners.
George Labs and Statistics Austria will each provide an actual use case, that will be used for validating the feasibility of the approach with actual data. The appropriate model architectures will be selected based on the findings of the simulation study, and then, these models will be trained on the actual data. Subsequently, these models will used for generating synthetic, privacy-preserving datasets that will be assessed by the data providers.
WP7 – Exploitation & Dissemination
WP7’s goal is to assist in the discussion and documentation the developed technology as well as to disseminate the findings of this project within the relevant academic and industry audience.
To help disseminate the findings, the consortium partners will initiate and participate in a critical discourse on the project findings with all relevant academic and industry audiences. This includes a continuous updating of working papers, the documentation and distribution of findings via a project webpage and the participation in relevant (academic and industry) conferences and workshops.